(一)简单爬取标题 up 播放量等表面数据
- 前提准备
- b站排行榜链接 https://www.bilibili.com/ranking
- python编译器一个
- 所需要的库:urllib3 BeautifulSoup
2 . 观察
打开b站排行榜页面,按F12或者鼠标右键检查页面,可以查看b站排行榜页面源码。当你鼠标在源码出浏览时,对应网页部分会高亮提示,可以看到代码对应的网页内容。
3.伪装
作为一个爬虫,要先把自己伪装成一个浏览器。在浏览器按F12后,点击 <网络> 选项
找到请求标头
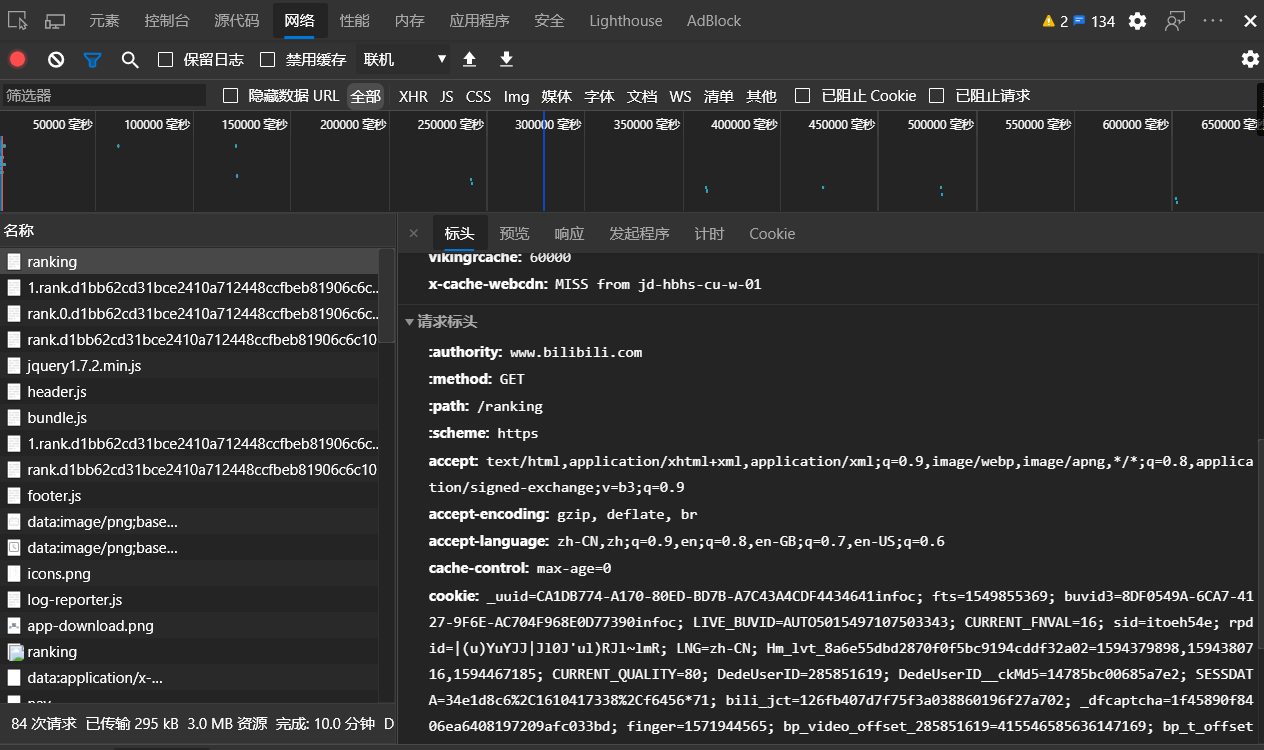
这些就是你浏览器的信息
这次我们只需要用到user-agent这个内容
import urllib3
import urllib.request
from bs4 import BeautifulSoup
def askURL(url):
headersss={
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36 Edg/83.0.478.61",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"
}
req=urllib.request.Request(url=url,headers=headersss)
#html="null"
try:
response=urllib.request.urlopen(req)
html=response.read().decode('utf-8')
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
剩下的过几天续上。。。